
Mireo SpaceTime was designed to easily manipulate huge amounts of structured spatiotemporal data. We built a distributed storage engine capable of storing and indexing trillions of entries. Our next step was to figure out a good way to query that data. We decided to use SQL because of its popularity. After some quick research we built our own SQL query parser, optimizer, and execution engine based on the classical volcano model. The implementation was quick and simple. Unfortunately, it was not very fast. This blog post talks about things we learned, mistakes we made, and ways in which we were able to drastically improve the query evaluation times.
Query evaluation
Let's start by explaining what happens when you run an SQL query. If you've ever formally studied databases, you probably know that the query text is first parsed, then semantically verified, optimized, and finally executed. The query is represented as a tree of relational operators. This tree is then optimized logically and physically (relying on relational algebra and cost estimations), thus producing an estimated execution plan. Discussing the exact methods of relational tree optimization would be out of the scope of this short text, some very elaborate books are still being written about the topic. The process of deriving the query execution plan is sometimes referred to as query compilation. Note that this does not necessarily mean that any native machine code is generated (as is the case when compiling e.g. C/C++ source code).
OK, we have an execution plan, but how do we get the actual query results? In the classical approach known as volcano model (or iterator model), each relational operator produces a stream of tuples, which is accessed through an iterator interface (e.g. open, next and close). Each next call produces a new tuple from the stream, if available. The query output is obtained by repeatedly calling next on the root of the tree, which calls next on its children as necessary, etc. This is a very simple and straightforward approach which works fine, but requires excessive amount of CPU time. The next call is usually a virtual function call, and it might be called millions of times. Additionally, even very small tuples must be materialized in memory before they are to be consumed by an operator, they can not remain in CPU registers. If the query execution is bottlenecked by I/O and CPU usage is not important, then this approach is acceptable.
Benchmarking the volcano
Mireo SpaceTime, however, offers huge I/O throughput. Applying volcano model to Mireo SpaceTime is not the optimal approach. This is easy to demonstrate if we take a look at an example. Consider the following query:
SELECT vid, SUM(SPHERE_LENGTH(x[0], y[0], x[1], y[1])) AS dist FROM st.segments GROUP BY vid
The purpose of this query is to show total distances traveled for each vehicle. The table segments contains vehicle trajectories stored as sequences of line segments on a sphere. Each segment is specified by a pair of coordinates (x[0], y[0]), (x[1], y[1]). The query groups rows by column vid (vehicle id), calculates the length of each segment (by calling the sphere_length function), and sums them up to obtain total distance for each vehicle. This query represents a very typical SpaceTime use case.
Let's take a look at the optimized relational tree for this query:
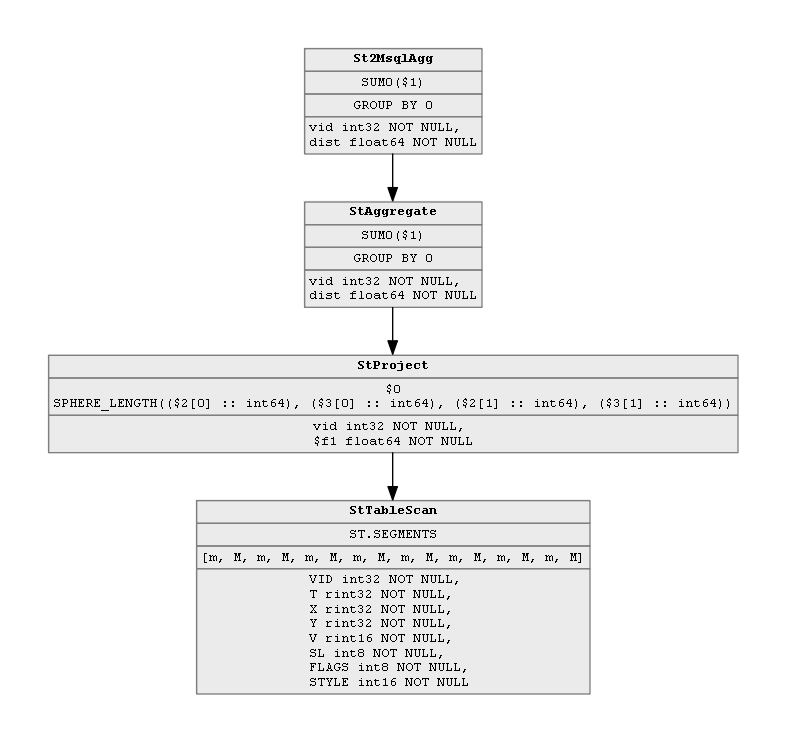
The tree is a simple chain of nodes, each node representing a single relational operator. The last node in the chain is StTableScan, which stands for SpaceTime table scan operator. It performs a scan of the table segments. Its parent node is StProject (SpaceTime project operator), which preserves the vid column, calculates the segment lengths and discards all other columns.StAggregate node then groups the rows by values found in the first column (vid), and sums the values in the second column (the calculated lengths). Mireo SpaceTime is a distributed system, so all of this has to happen on each SpaceTime server node. Each SpaceTime server will produce a table containing aggregated vehicle distances of whatever vehicle data is actually stored on that server. The job of the root operatorSt2MsqlAgg (SpaceTime-to-Mireo-SQL) is to aggregate all of distributed results into a single table (by grouping by column vid and summing the distance column once again). Generally speaking, a Mireo SQL relational tree consist of subtrees which are executed on distributed nodes and then combined on a single node in a map-reduce fashion. Reduced results are then processed by the remaining part of the relational tree on that same node, thus producing query results.
In order to benchmark our simple volcano-based interpreter, we ran this query in a non-distributed environment, on a single server, on a small database containing around 25 million segments. The total running time was around 17 seconds. To check if we can do better, we also wrote a small program in C++ that achieves the same task by calling SpaceTime primitives directly. It produced the same results in about 0.5 seconds, showing there was a lot of room for improvement. We wanted to get as close to C++ level of performance as possible.
A better design
It was obvious that our queries were bottlenecked by the CPU, not I/O. To improve this, we tried a different approach, proposed in [Neumann 2011]. The key characteristics of this approach are:
- Processing is data-centric, not operator-centric.
- Data is processed in such a way to keep it in CPU registers as long as possible.
- Data is not pulled by operators, but pushed towards operators, which improves code and data locality.
- Queries are compiled into native machine code using the LLVM compiler library.
Compiling to native machine code is by far the most complex step in this framework. We do not produce the native code directly. Instead, we output the LLVM Intermediate Representation (IR) code (a low level language similar to assembly). The LLVM compiler library optimizes and transforms the IR code to target native CPU code. In our distributed system, only one node performs query parsing, optimization and the IR code generation. The generated IR code is then transmitted to all other nodes, where it is compiled, linked and executed. The generated code is platform-independent, i.e. we can generate it on a Windows machine, and execute it on a Linux (Debian) server.
As described in [Neumann 2011], parts of the execution engine are written in C++ (e.g. hash-tables, index structures), and are accessed through LLVM's native C calls. The IR generator source code is readable, elegant, and not very long (around 10 000 lines). To give you an idea, here is a sample:
mb.if_(ctx.no_rt_error(), then_{
insert_defaults_if_empty(mb, ctx, this, agg_ptr);
mb.extern_call("agg_init_result_iter", agg_ptr);
mb.loop_("agg_result_loop", body_{
ctx.insert_standard_cancel_check(break_);
Value* entry = mb.extern_call("agg_next_result_val", agg_ptr);
break_(mb.is_zero(entry));
ctx.dematerialize_row(entry, *schema());
parent_consume(mb, ctx);
});
});
This snippet checks for runtime errors before iterating over the results of the aggregation operator. The loop checks for possible query cancellation requests, fetches the next result row, dematerializes it and finally calls the parent_consume function to generate the code required by the parent relational operator. The dematerialization step is converting the row in-memory representation into a set of LLVM values. The LLVM optimizer is able to determine which of the values are actually used by subsequent code, and possibly load some or all of them into CPU registers.
Interpretation vs Compilation
Native compilation is not something that most current database management systems do. Is it really that important? What are the benefits of natively compiled over interpreted code, anyway? To illustrate this point, let's consider a simple binary expression "A + B".
When an interpreter encounters this expression, it needs to:
- check that both A and B exist
- check that the + operator is defined for current types of A and B
- perform type conversion if necessary (e.g. transform an integer to a floating point)
- perform the addition operation
These steps might involve hash-table lookups, virtual function calls, switch statements, etc. This could easily take a lot of CPU cycles.
Compiler needs to do almost the same steps:
- check that both A and B exist
- check that the + operator is defined for current types of A and B
- emit the code to perform type conversion if necessary (e.g. transform an integer to a floating point)
- emit the code to perform the addition operation
The difference is in steps 3 and 4 which don't actually perform the addition but, only emit the code that will perform the addition. The interpreter performs each instruction immediately, while the compiler only produces the code that will perform the instruction at a later time.
Consider the implications in the context of running a simple SQL query such as SELECT A + B FROM table, where A and B are integer columns. The interpreter has to run a complex code to add two integers A and B for each row of the table. The compiler only has to run this complex code once. After the existence and data types of A and B are checked, the compiler outputs a single instruction that adds two integers, which will then be executed once per resulting row. If the table contains millions of rows, it is clear that we would want to compile this query.
But that is not all. Consider the expression (A+B)*C. While evaluating this expression, the interpreter needs to figure out a location where to store and how to represent the value A+B before multiplying it by C. Temporary values could be stored in a variant (e.g. std::variant in C++), or as instances of classes derived from a AbstractValueClass or something similar, but their memory footprint will be significantly larger than 4 bytes required to store a simple 32-bit integer. More importantly, it will be impossible to store the temporary values in CPU registers. The compiler, on the other hand, has no issues with this: it will emit the instruction to calculate A+B and store the result in a CPU register, then multiply the value in the register by C.
These are some of the reasons why compiled programs generally run faster than interpreted, up to several hundred times (e.g. C++ g++ vs Python 3 fastest programs).
But is it worth it in case of SQL? To put it simply: yes, absolutely. Remember our example query ? The one that took 17 seconds to complete under volcano model interpreter?
Now it only takes 0.6 seconds, including the 60 ms compilation time. That is quite close to the 0.5 running time achieved by hand-written C++ code.
Conclusions and closing remarks
We built a distributed database which we can query using standard SQL. The system is characterized by very fast I/O, so we needed to avoid excessive CPU usage during query execution. Initial benchmarks indicated that the classical volcano model was unsuitable for the task. Instead, we implemented the approach proposed in [Neumann 2011], which is data-centric, pushes the data towards the relational operators, and compiles the queries into native machine code using the LLVM compiler library. The performance of this framework is on par with hand-written C++ code, as measured on exemplar queries on a single machine.
Since our system is distributed, we use a map-reduce approach to evaluate some parts of the query on multiple distributed nodes, gather the results on a single node and process them further as necessary. A single node (chosen by the load balancer) parses the query and generates the optimized relational tree. The same node generates a separate LLVM IR bitcode for each of the subtrees that need to be evaluated on the remote nodes. The remote nodes only need to link and blindly execute the received bitcode, they do not need to know anything about the underlying SQL. This means the interface between the nodes is simple, which is an important property in federated multi-tenant database systems.
If you want to find more detailed information about the SpaceTime solution, visit our definitive guide through an unusual and fundamentally new approach of using spatiotemporal data in our everyday routine.


